안녕하세요
이번에는 각 회사에서 Data Science를 통해 사업 경쟁력을 높이려 하지만
실질적으로 성과가 미미한 이유에 대해 조직 측면에서 알아보려 합니다.
[Data Science]
먼저 Data Science에 대해서 알아보면 WiKi에서는 아래와 같이 정의하고 있습니다.
"데이터 마이닝(Data Mining)과 유사하게 정형, 비정형 형태를 포함한
다양한 데이터로부터 지식과 인사이트를 추출하는데 과학적 방법론"
간단하게
평범한 데이터 집합에서 Data Insight를 분석/도출하는 분야라고 할 수 있습니다.
[왜 기존 산업영역에 DataScience가 중요해졌는가]
BigData+AI가 급격하게 발전되기 이전의 Data Science는 가치가 높지 않았습니다.
그 때는 Data Science라기 보다는 정적데이터 기반 Business Intelligence 분야가 더 활성화 되어있었습니다.
하지만
동적 데이터 기반의 BigData + AI가 발전하며 Data를 통한 예측이 정교화되었으며
고객에게 Personalize된 서비스를 제공하는 산업의 성장이 발전하기 시작했습니다.
가장 잘 아시는 회사가 YouTube이며
Data라는 것은 쌓이면 쌓일수록 가치를 발현하며 사업영역에서 Winner Takes All의 확률이 올라갔습니다.
하지만 각 산업영역의 기존 대형 플레이어들은 빠른 Digitalization을 하지 못하였으며
Big Blur 시대 아래와 같은 새로운 경쟁에 직면하게 되었습니다.
YouTube로 인한 방송컨텐츠의 경쟁
FinTech기업의 등장으로 인한 금융산업의 경쟁
마켓컬리 등의 등장으로 인한 식품/물류산업의 경쟁
Ride-hailing, Ride-Sharing으로 인한 교통산업의 경쟁
위와 같은 IT기반 회사의 특징은
고객Data의 분석을 통한 최적화된 개인화서비스(Data Science)를 제공하는 것이 특징이며
기존 산업의 플레이어도 이에 대응하기 위해
자연스럽게 Data Insight를 통한 신규서비스 제공을 고민하게 되었고 최근에는 빠르게 도입하고 있습니다.
하지만
많은 기업들이 BigData, AI를 통한 Data Science 전문가들을 고용했지만
명확한 성과가 나오질 않고 오히려 Startup에 시장을 잠식당하는 현상이 나타났습니다.
Data Science를 위한 인프라, 인력, 조직 등이 갖추어 졌는데 대체 왜 경쟁력있는 서비스가 나오지 않는가?
여기에 대해서는 저는 기존 산업의 조직 구성 측면에서의 문제점을 말하고 싶습니다.
[기존산업의 AS-IS 조직 구성의 문제점]
결론부터 말씀드리면 기존 기업들의 일반적인 조직 체계는 Data Science를 위한 조직에 적합하지 않습니다.
이미 모든 조직은 Data Science팀을 만들기전 체계화된 조직을 가지고 있습니다.
그래서
Digital Transform을 진행 시 정형화된 예전 조직은 그대로 두고 Digital본부를 Add하는 형태로 진행합니다.
아래는 기업의 일반적인 조직구조 체계 예시입니다.

하지만
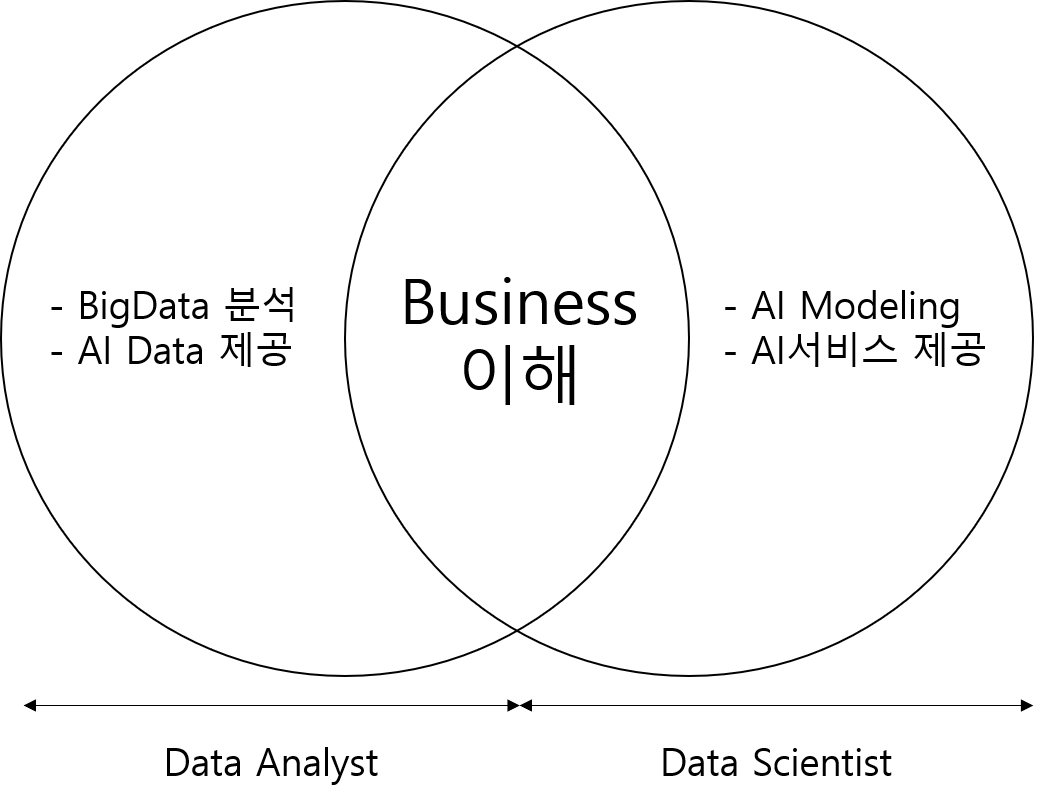
Data Science를 통한 Insight의 도출의 가장 중요한 구성요소는
통계지식과 더불어 "업무 도메인의 명확한 이해"입니다.
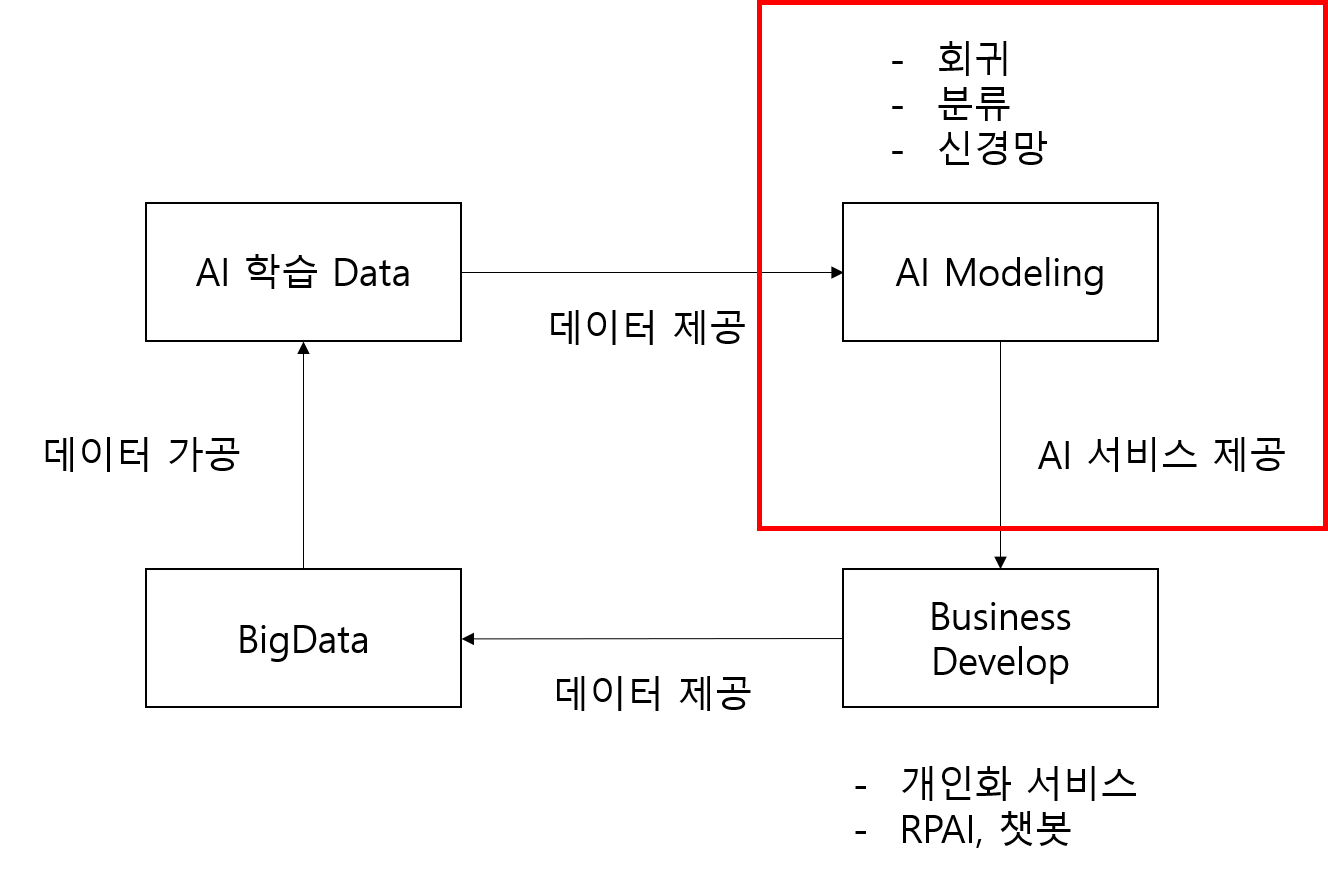
위와 같은 조직체계로는 AI, BigData 부서에서 Data가 어떻게 생성/관리되는지 명확히 이해하지 못합니다.
Data Analysis, Science를 하려고해도 업무 프로세스와 특징, 특정 데이터에 대한 명확한 의미를 알지 못하면
단순한 패턴 도출은 가능할지 몰라도, 회사의 경쟁력있는 서비스의 도출은 한계가 존재합니다.
아래 그림으로 보면 Data 생성/관리/분석 프로세스의 Silo가 존재하여 비효율성이 존재하는 것입니다.

따라서 우리는 Data Science를 통한 신규서비스 창출 및 Insight도출을 위해
"Cross Functional Team" 조직구성이 필요합니다.
[Cross Functional Team]
Cross-functional team의 정의는 Wiki에서 아래와 같이 정의하고 있습니다.
"서로 다른 기능 전문가들이 공통적인 목표를 위해 구성된 그룹"
(A cross-functional team is a group of people with different functional expertise working toward a common goal)
기업은 Data Scientist가 Data의 명확한 분석/모델링을 할 수 있게 Cross Functional한 조직을 구성해야합니다.
그래야 Data Scientist가 Data의 생성/ 관리를 명확히 알 수 있고, Insight를 도출하기 때문입니다.
아래 예시에서 보듯이
Payment팀의 개발자와 Data Scientist가 상호 한 팀으로 업무를 하는 것을 통해서
서로 간의 업무 이해도 증진, 빠른 이슈 공유 및 서비스 개발, Data Insight 도출이 가능할 것 입니다.
많은 분들이 MSA, Container기반의 Cloud가 도입되어야 Cross-functional team이 의미가 있을것이라 하지만
금융, 물류, 공장 등의 기간 산업들은 빠르게 Cloud가 도입될 수 없는 사정을 고려해보면
아래와 같은 Cross-functional team 선제적으로 도입함으로써
업무 효율성 뿐만 아니라 조직 문화를 바꿔나가는 것도 좋다고 생각합니다.
감사합니다.

'Data' 카테고리의 다른 글
| AI시대의 Data Scientist와 Data Analyst (0) | 2020.03.14 |
|---|---|
| MyData Declaration - Mydata Global Network (0) | 2020.02.16 |