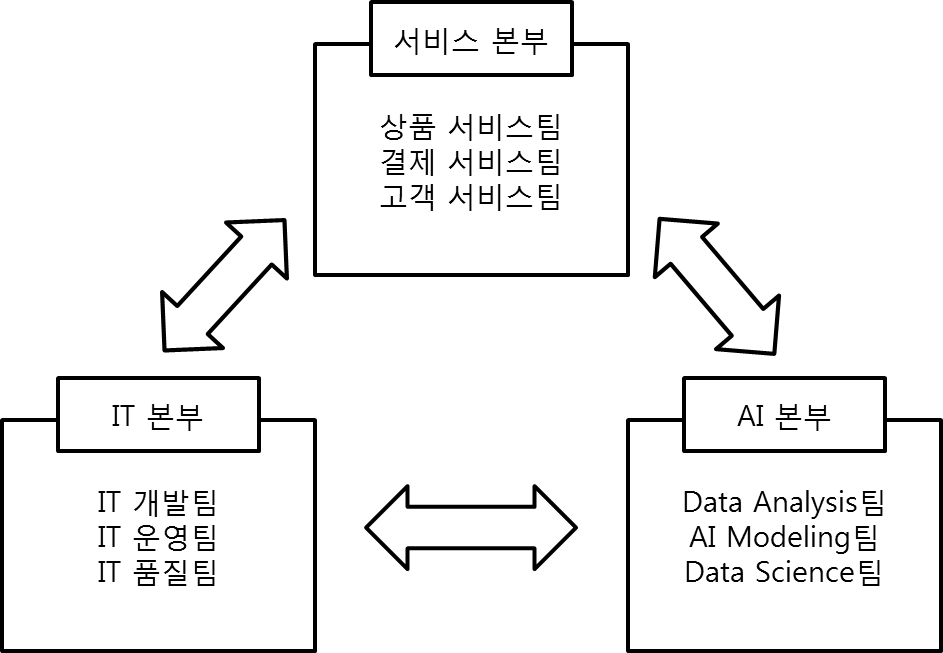
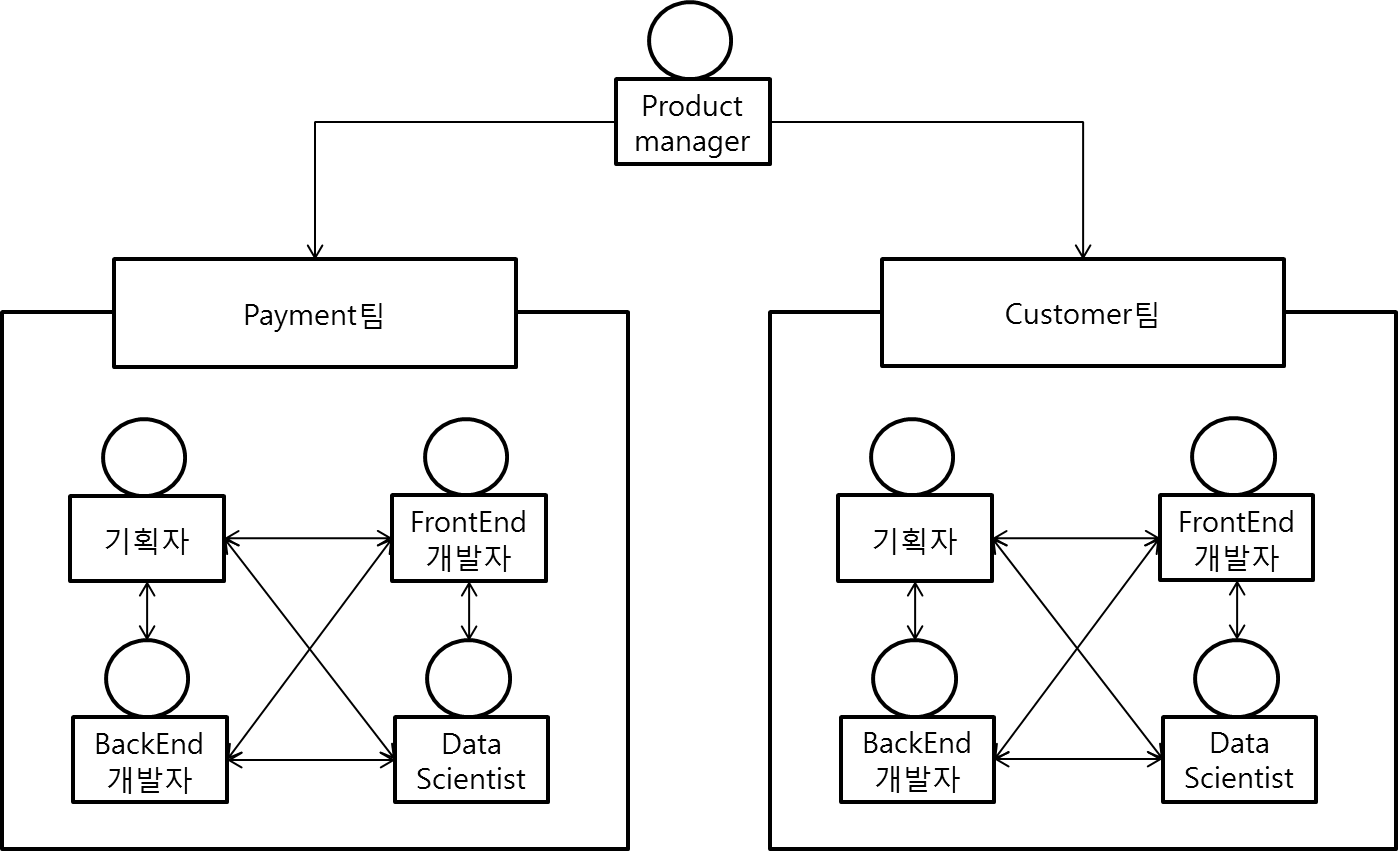
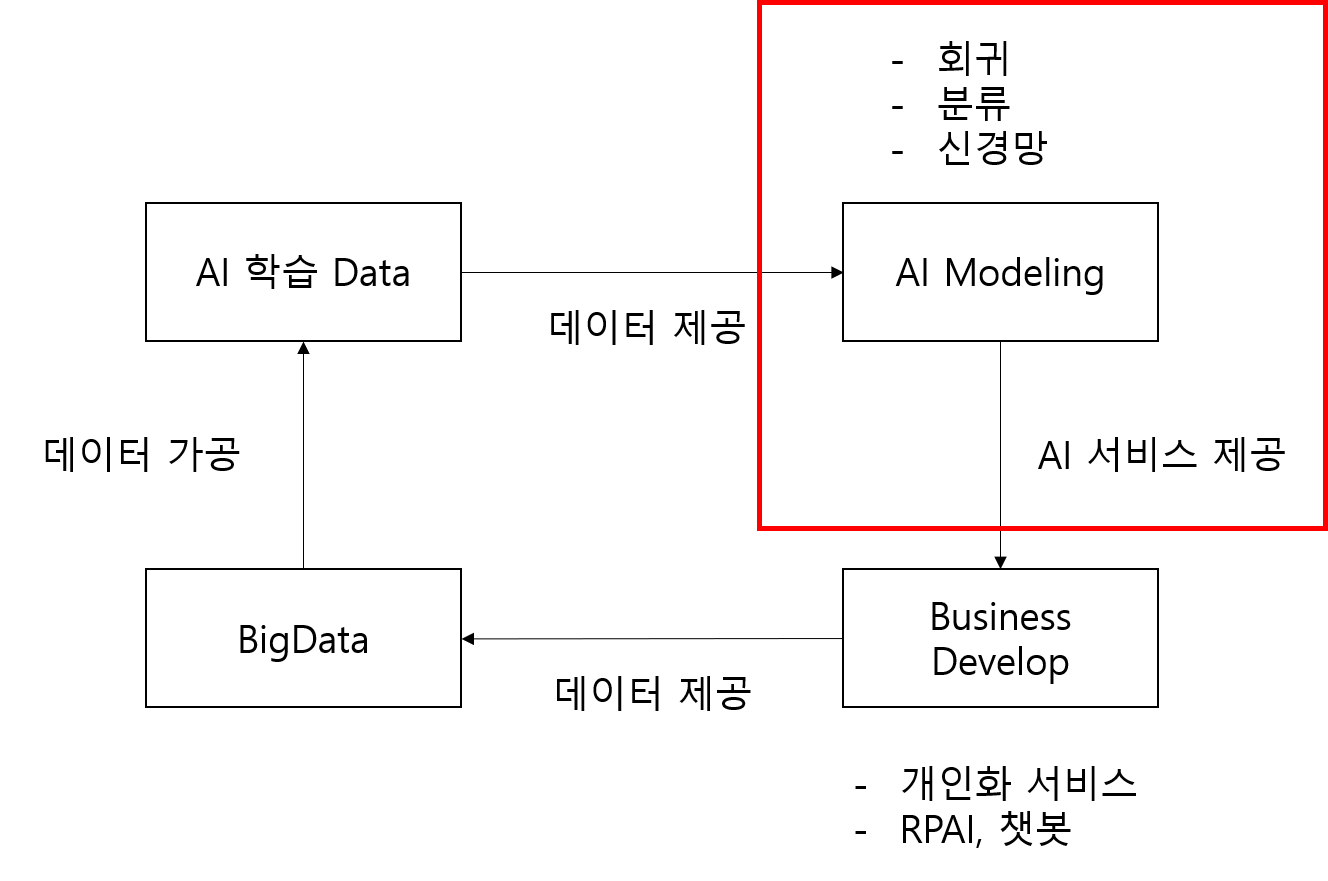
"필요가 발명의 어머니라면 발명의 아버지는 끈기, 즉 손실을 줄이고 편히 생활할 수 있는 곳으로
옮겨가기보다 끝까지 불리한 조건 밑에서 살아가야겠다고 품는 결의라고 할 수 있다.
이것이 진보의 역설적 진리다.
네 번 되풀이된 빙하시대 특징인 기후와 동식물의 성쇠기에 우리가 아는 문명이 시작되었다는 것은
결코 우연이 아니다.
울창한 숲이 말라죽어 갈 때 간신히 달아난 영장류는 자연법칙의 지배를 받는 것 중에서도 가장
으뜸가는 지위를 확보했고 마침내는 자연을 정복하기 시작했다.
어려움을 뚫고 나가 결국 인간이 된 이들은 이미 앉을 나무조차 없어진 그 자리에 버티고 있던 무리
나무 열매가 익지 않을 때 대신 고기를 먹던 무리
햇빛을 따라 쫒아가는 대신 불과 옷을 만든 무리
살던 곳에 견고한 방벽을 쌓아올리고 아이들을 훈련하여 비합리적으로 보이던 세계의 합리성을 입증해보인 무리였다."
따라서 주역인 인간이 겪는 시련의 첫 단계는 동적인 행동을 통한 음에서 양으로의 이행이다.
동적인 행동은 악마의 유혹을 받는 신의 피조물이 행하는 것으로, 이것은 신으로 하여금 또 다시 창조 활동을 개시할 수 있게 해준다. 그러나 이러한 진보에는 지불해야하는 대가가 따른다. 그리고 그 대가를 지불하는 것은 신이 아니라 신의 종, 즉 씨앗을 뿌리는 인간인 것이다.
At the same time, Artificial Intelligence (AI) entails a number of potential risks, such as opaque decision-making, gender-based or other kinds of discrimination, intrusion in our private lives or being used for criminal purposes
-> 결과를 설명하지 못하는 AI, 성별 차별, 사생활 침해 등의 AI 문제에 대한 접근이 필요
Thus, the Commission supports a regulatory and investment oriented approach with the twin objective of promoting the uptake of AI and of addressing the risks associated with certain uses of this new technology.
The purpose of this White Paper is to set out policy options on how to achieve these objectives.
-> 위원회는 규제 측면과 AI 투자 측면에서 지원하고,
EU AI 백서는 이러한 목표들을 어떻게 달성시키는지 정책적 Option을 주는 것이 핵심
[1. INTRODUCTION]
Europe can combine its technological and industrial strengths with a high-quality digital infrastructure and a regulatory framework based on its fundamental values to become a global leader in innovation in the data economy and its applications as set out in the European data strategy.
On that basis, it can develop an AI ecosystem that brings the benefits of the technology to the whole of European society and economy
-> EU의 기술적 산업적 강점과 높은 수준의 디지털 인프라를 결합하고
유럽이 Global Leader가 되고자 하는 "규제 Framework"를 통해 EU AI 생태계를 만들것이라는 것이 핵심
여기서 가장 중요한 부분은 규제 Framework인데 EU는 GDPR에서 보았지만 항상 규제를 통한 안전성을 중점으로 두고 있음
EU 내 AI산업도 GDPR과 같이 안전성, 신뢰성을 기반이 되는 구체적 규제가 나올 것으로 예상
[2. CAPITALISING ON STRENGTHS IN INDUSTRIAL AND PROFESSIONAL MARKETS]
In response, Europe needs to increase its investment levels significantly. The Coordinated plan on AI developed with Member States is proving to be a good starting point in building closer cooperation on AI in Europe and in creating synergies to maximise investment in the AI value chain.
-> EU에서 AI 투자를 증대시킬 것이기 때문에
EU 내 AI산업은 생태계와 가치 사슬의 형성에서 좋은 시작점일 것임
[3. SEIZING THE OPPORTUNITIES AHEAD: THE NEXT DATA WAVE]
The volume of data produced in the world is growing rapidly, from 33 zettabytes in 2018 to an expected 175 zettabytes in 2025. Each new wave of data brings opportunities for Europe to position itself in the data-agile economy and to become a world leader in this area.
-> 지속적으로 증가하는 데이터의 양은 EU에게 데이터 경제의 리더가 되게 할 것.
내용 전체에 나오는 AI에 필수적인 저전력 전자, 양자컴퓨팅 등에서 강점을 가지고 있으며
이런 산업들을 기반으로 연계해 AI 시대의 리더가 될 것
[4. AN ECOSYSTEM OF EXCELLENCE]
[A.WORKING WITH MEMBER STATES]
EU-level funding in AI should attract and pool investment in areas where the action required goes
beyond what any single Member State can achieve
-> 단일 국가가 아닌 EU 레벨에서의 AI 산업을 위한 자금 유치 진행
[B. FOCUSING THE EFFORTS OF THE RESEARCH AND INNOVATION COMMUNITY]
Europe cannot afford to maintain the current fragmented landscape of centres of competence with
none reaching the scale necessary to compete with the leading institutes globally.
-> 세계 리딩 기업과의 경쟁을 위해 단편화된 센터를 유지하지 말고 조정 및 네트워킹 할 필요성이 존재
The centres and the networks should concentrate in sectors where Europe has the potential to
become a global champion such as industry, health, transport, finance, agrifood value chains,
energy/environment, forestry, earth observation and space.
-> AI 센터들은 강점이 있는 산업, 건강, 운송, 금융, 농식품, 에너지, 환경, 임업 등에 집중할 필요가 있음.
[C. SKILLS]
Developing the skills necessary to work in AI and upskilling the workforce to become fit for the
AI-led transformation will be a priority of the revised Coordinated Plan on AI to be developed
with Member States.
-> AI 교육이 조정되는 계획에서 우선이 될것
[D. FOCUS ON SMES]
It will also be important to ensure that SMEs can access and use AI. To this end, the Digital Innovation
Hubs and the AI-on-demand platform should be strengthened further and foster collaboration
between SMEs.
-> 중소기업 또한 AI에 접근이 가능하도록 지원을 해주는 것이 핵심
Digital Innovation Hubs, AI-on-demand platform 등을 통해서 지원
[E. PARTNERSHIP WITH THE PRIVATE SECTOR]
It is also essential to make sure that the private sector is fully involved in setting the research and
innovation agenda and provides the necessary level of co-investment
-> 민간 부문이 연구 및 혁신 의제 설정에 전적으로 참여, 필요한 공동 투자 수준을 제공하는 것이 필수.
[F. PROMOTING THE ADOPTION OF AI BY THE PUBLIC SECTOR]
It is essential that public administrations, hospitals, utility and transport services, financial supervisors,
and other areas of public interest rapidly begin to deploy products and services that rely on AI in their
activities.
-> 공공 부문의 산업에 AI를 빠르게 적용하는 것이 필수.
[G. SECURING ACCESS TO DATA AND COMPUTING INFRASTRUCTURES]
Promoting responsible data management practices and compliance of data with the FAIR principles
will contribute to build trust and ensure re-usability of data.
-> 책임있는 데이터 관리, 공정성에 기반한 데이터 준수를 통해 데이터 보안을 확보
[H. INTERNATIONAL ASPECTS]
The EU will continue to cooperate with like-minded countries, but also with global players, on AI,
based on an approach based on EU rules and values (e.g. supporting upward regulatory convergence,
accessing key resources including data, creating a level playing field)
-> EU 규칙 및 가치에 기반한 접근 방식으로 다른 국가들과 협력하겠다는 의미
[5. AN ECOSYSTEM OF TRUST: REGULATORY FRAMEWORK FOR AI]
[A. PROBLEM DEFINITION]
A regulatory framework should concentrate on how to minimise the various risks of potential harm,
in particular the most significant ones. The main risks related to the use of AI concern the application
of rules designed to protect fundamental rights
-> 규제 Framework는 잠재적인 위험을 최소화 하기 위해 집중해야할 필요
[B. POSSIBLE ADJUSTMENTS TO EXISTING EU LEGISLATIVE FRAMEWORK RELATING TO AI]
While the EU legislation remains in principle fully applicable irrespective of the involvement of AI,
it is important to assess whether it can be enforced adequately to address the risks that AI systems
create, or whether adjustments are needed to specific legal instrumentsFor example, economic actors
remain fully responsible for the compliance of AI to existing rules that protects consumers, any
algorithmic exploitation of consumer behaviour in violation of existing rules shall be not permitted
and violations shall be accordingly punished.
-> AI 관련과 관계없이 EU 법규는 원칙적으로 완전히 적용 가능한 상태로 유지
AI가 생성하는 위험을 해결하기 위해 적절하게 시행 될 수 있는지 또는 특정 법적 수단에 조정이 필요한지
여부는 평가하는 것이 중요
[C. SCOPE OF A FUTURE EU REGULATORY FRAMEWORK]
The working assumption is that the regulatory framework would apply to products and services
relying on AI. AI should therefore be clearly defined for the purposes of this White Paper,
as well as any possible future policy-making initiative.
-> 규제 Framework가 AI에 의존하는 제품 및 서비스에 적용.
따라서 AI는 EU AI 백서의 목적과 미래의 모든 정책 결정 이니셔티브를 위해 명확하게 정의
[6. CONCLUSION]
The European approach for AI aims to promote Europe’s innovation capacity in the area of AI while
supporting the development and uptake of ethical and trustworthy AI across the EU economy.
AI should work for people and be a force for good in society.